
I’ve been wondering what LLMs mean for language design and implementation. Some believe that, because language models are obviously trained on existing content, they are inherently less capable of assisting users with new programming languages. Intuitively this makes sense. However:
- Simon Wilson has a “hunch” that LLMs actually make it easier to build a new programming language;
- Richard Felman has argued that this might be the “best time to create new programming languages”;
- Maxime Chevalier has been developing her own experimental programming language called Plush, porting “many example programs with the help of LLMs”.
If anything, LLMs might be shifting the cost of programming language development economics, making it possibly even simpler to build your own. As a self-professed “programming-language nerd” and compiler-enthusiast, that just makes me excited.
Disclaimer: you should not think of this as of a fully-fleshed out essay, rather it is a collection of ideas that I just want share in the hope to spark some interesting conversation! Some code examples have been generated using Claude and a bit of Python. If you find mistakes, let me know!
Domain-Specific Languages and Language-Oriented Programming 🔗
One of my favorite articles about domain-specific languages is a classic from 1994 where M.C. Ward introduces the idea of Language-Oriented Programming. In essence, LOP extends the idea of designing a large software system in layers, with one layer being a language definition.
 The 'middle-out' diagram found in the paper next to the poster for the Silicon Valley series, where 'middle-out compression' is discovered over a decidedly NSFW argument
The 'middle-out' diagram found in the paper next to the poster for the Silicon Valley series, where 'middle-out compression' is discovered over a decidedly NSFW argumentRather than traditional top-down or bottom-up development, LOP proposes a “middle-out” approach:
- Design a domain-oriented language suited for the specific problem domain
- Split development into two independent parallel tracks:
- Implement the system using this middle-level language
- Implement a compiler/interpreter for the language
Domain-Specific Languages are small languages designed to focus on a specific aspect of a software system. We deal with DSLs every day: SQL can be considered a DSL, LaTeX is a DSL, AWK is a DSL, Kubernetes’ YAMLs are a DSL. They are “domain-specific” because they are used to write code for a given “subdomain” of the software system. In this sense, they have been also described as a means of communcation between a developer and a “domain-expert”. The holy grail of computing for many years was to let such “domain experts” write the code themselves, while developers would only validate it and deploy it in the large system.
Now it so happens that coding agents are pretty good at generating code, to the point that Andrey Karpathy claimed that “The hottest new programming language is English”!
So, I’ve been thinking: what if instead of just generating code for the languages that LLMs already have in their training set, we instead let them generate the implementation of a domain-specific language, and then use that throughout the rest of a coding session?
But then, what would one such language look like? Sergei Egorov shared a thread with his thoughts on a similar matter. I myself I’ve been wondering if a programming language for LLMs would be some kind of mixture between a high-level and a low-level language: in that we want the language to be terse, but at the same time low-level enough to implement some kind of VM for it.
Then again, what would “terseness” mean in this context?
Detour: Token-Efficiency in Programming Languages 🔗
Traditional programming languages optimize for human readability, not for token efficiency within an LLM’s “context window”1.
From a language design perspective, there’s a fundamental mismatch in how “tokens” are defined: while programming language tokenizers split text at whitespace and symbols (which are then usually dropped after parsing), language models treat tokens very differently.
For instance, in a JS tokenizer, the control-flow structure:
for (let i = 0; i <= 10; i++) {
print(i);
}
would be tokenized as follows (notice how similar types of tokens are color-coded the same)
for(let·i·=·0;·i·<=·10;·i++)·{·print(i,·j);·}
this in turn, would correspond to a “parse tree” of the form:
ForStatement
├── Init: VariableDeclaration (let)
│ └── VariableDeclarator
│ ├── Identifier: i
│ └── Literal: 0
├── Test: BinaryExpression (<=)
│ ├── Identifier: i
│ └── Literal: 10
├── Update: UpdateExpression (++)
│ └── Identifier: i
└── Body: BlockStatement
└── ExpressionStatement
└── CallExpression
├── Identifier: print
└── Arguments
└── Identifier: i
But, for the tokenizer of an LLM, no further structure is detected before inference; the token stream would look something like the following2, where there is no longer any relation between colors and content (in fact, in this representation matching colors do not qualify the kind of token)
for·(let·i·=·0;·i·<=·10;·i++)·{ ·print(i); }
In other words, because the tokenizer of an LLM is trained on a vast amount of varied text, it is not specifically optimized for code; semantically equivalent code can have wildly different token counts based purely on formatting choices, identifier naming, or even the presence of comments.
For instance, complete words like user, authentication, and token tend to be learned as single units; rare abbreviations (Tkn) may be split into multiple character-level tokens (T, k, n); symbols usually count as single tokens. It follows that:
- a loop written with short variable names like
iandjdoes not necessarily consume fewer tokens than one calling them, respectivelyouterandinner; - in general, verbose but clear variable names using common English words (
userAuthenticationToken) may be more token-efficient than abbreviations (uatorusrAuthTkn); - code that might look compact can still be token-heavy for a language model; comments, symbols and whitespace are often often transformed, abstracted or even dropped during parsing; however, in LLM tokenization, these syntactic construct will usually persist.
Let’s consider a few examples.
Example 1: JavaScript vs Python 🔗
When it comes to token-efficiency, a language like Python might compare more favorably to Javascript. Even in code where complexity is comparable, Python uses fewer symbolic delimiters, favoring whitespace and full words instead. Consider:
for(let i = 0; i <= 10; i++) { for(let j = 0; j <= 5; j++) { console.log(i, j); } }
Python (short variable names): 21 tokens (51% vs JS)
for i in range(11): for j in range(6): print(i, j)
Python (readable names): 22 tokens (49% vs JS)
for outer in range(11): for inner in range(6): print(outer, inner)
Of course, you might argue that the example above is somewhat contrieved (it’s just two nested loops). Let’s consider another example.
Example 2: APL vs Q vs Python 🔗
kdb+ is quantitative finance’s sweetheart; a somewhat obscure time-series DB, sporting an APL dialect called K, and a thin, more readable wrapper called Q, where symbolic identifiers are often traded for more explicit English words.
How does APL compare to an equivalent Q program, in terms of tokens? And what about Python with numpy and pandas (effectively using Python as an array-oriented DSL)?
Update Nov 11: The original version presented a broken 3-period weighted average; thus it also claimed, incorrectly, that the Python version was shorter (token-wise). Thanks to Adám Brudzewsky
In the following, we compute a 3-period moving average by symbol, selecting the symbols with average greater than 100. For instance, if we have:
data = {
'sym': ['A', 'A', 'B', 'A', 'B', 'A', 'B', 'C', 'C', 'C'],
'price': [100, 101, 95, 102, 98, 108, 105, 96, 98, 100]
}
the result is ['A'], because B and C’s average will be smaller than 100 at the end.
In Dyalog APL this is written as follows (assuming two vectors, sym and price, where each index correspond to a symbol, price pair):
sym ← 'A' 'A' 'B' 'A' 'B' 'A' 'B' 'C' 'C' 'C'
price ← 100 101 95 102 98 108 105 96 98 100
result ← (100<(+/÷≢)sym(¯3↑⊢)⌸price)/∪sym
result ⍝ // prints 'A'
Now, notice how the usage of Unicode characters explodes into several non-printable tokens:
Dyalog APL: 28 tokens
result·←·(100<(+/����)sym(¯3↑���)���price)/��sym
Somehow surprisingly, the same code in Q, even if it’s more readable and, some might argue, more verbose, has actually a slightly lower token count:
Q (kdb+): 26 tokens
select·sym·from·( ··select·sma:·avg·3#price·by·sym·from·prices )·where·sma·>·100
Unsurprisingly, the Python version has a higher token count. Depending on your meter, the difference is either quite large (about twice as many tokens!) or relatively small (just about 20–25 tokens!). Still, considering how much longer the Python version is in terms of characters compared to Q or APL, it’s interesting that the token count remains relatively low.
Python (numpy, pandas): 49 tokens
result·=·(prices ····.groupby('sym')['price'] ····.apply(lambda·g:·g.tail(3).mean()) ····.to_frame(name=' avg')· ····.query('acg·>·100').index.tolist())
Example 3: Token-Oriented Object Notation (TOON) 🔗
I like this example, because I did not come up with it. Johann Schopplich has proposed the “Token-Oriented Object Notation” (TOON), a more compact alternative to JSON. The authors claim “typically 30-60% fewer tokens on large uniform arrays vs formatted JSON”. In the words of its readme:
AI is becoming cheaper and more accessible, but larger context windows allow for larger data inputs as well. LLM tokens still cost money – and standard JSON is verbose and token-expensive:
{ "users": [ { "id": 1, "name": "Alice", "role": "admin" }, { "id": 2, "name": "Bob", "role": "user" } ] }TOON conveys the same information with fewer tokens:
users[2]{id,name,role}: 1,Alice,admin 2,Bob,user
TOON is a perfect example of a token-efficient DSL.
The Return of Language-Oriented Programming 🔗
A domain-specific language is by definition smaller in scope than a general-purpose language, so it should be easier to design and implement; moreover, if the language is designed well, it should lead to a more efficient usage of the context window.
If we can abstract away parts of our domain into a higher-level language, we can effectively use the LLM to
- generate the implementation of a DSL
- generate documentation and examples for such our DSL
- point the LLM to docs and examples and prompt it to generate more code using our DSL
So, instead of trying to come up with a general-purpose language for LLMs, we define a tiny DSL for each specific subsystem we mean to realize. The domain-specific Language is now not only a means of communication between a domain-expert and the developer, but also a means of communication between the developer, the domain-expert and the language model.
I’m going to show a couple of examples
Example 1: Piano DSL 🔗
Days ago, I stumbled upon Alexander Kaminski’ blog post about “microdiagram DSLs”:
The core concept is quite straightforward: instead of having one language for all diagrams, have multiple languages for various purposes. For example, this diagram is designed to help learn piano by illustrating the relationship between different keys.

I immediately wondered if I could generate something similar using Claude:
design a DSL to design piano diagrams like these:
https://xlii.space/eng/haskell-feels-easy/
then implement it in JS and show me some examples with their rendering
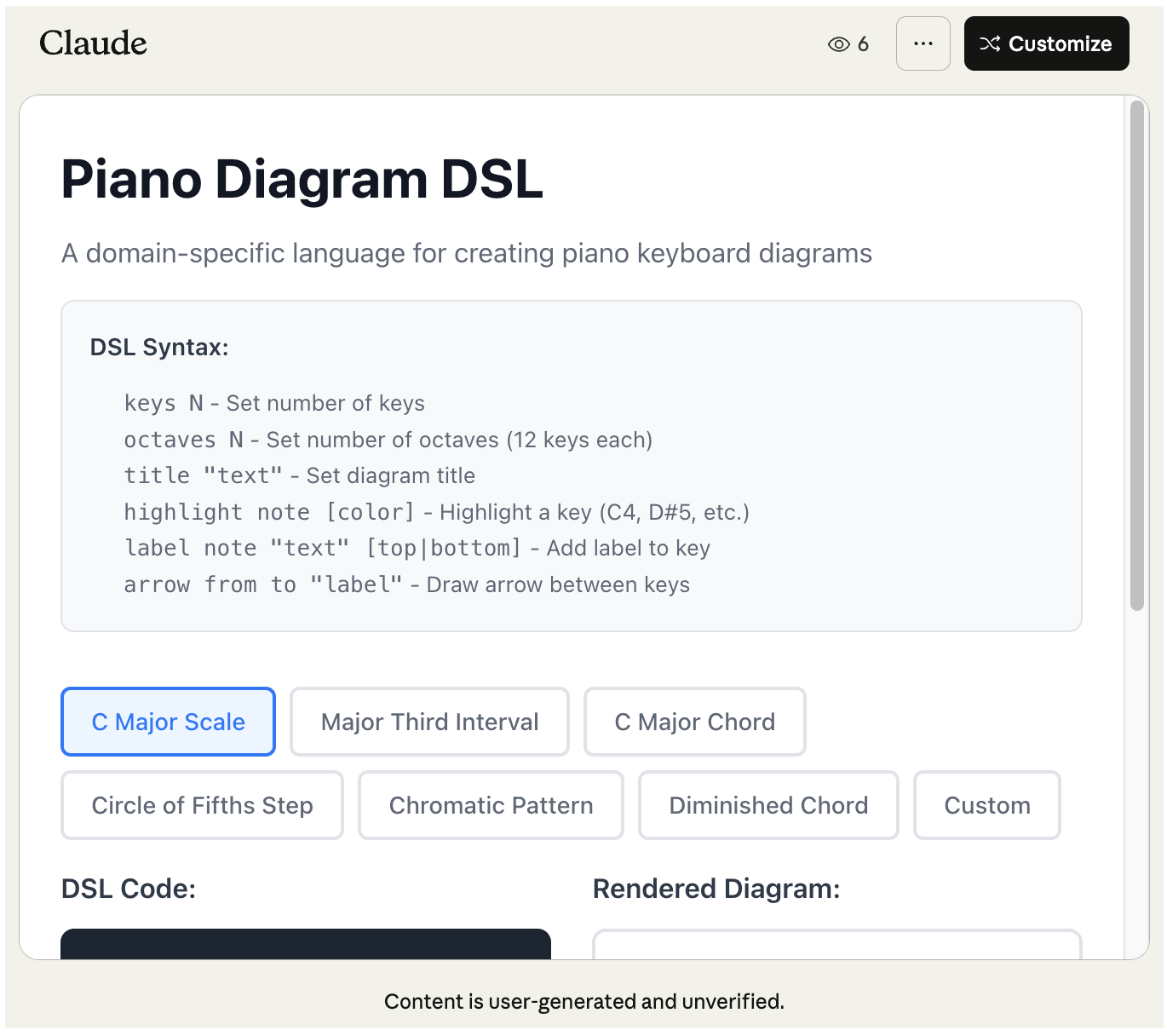
The implementation is fully-functional and interactive
Example 2: Business Rules 🔗
Another classic example of a DSL is Business Rules Languages. To be more precise, BRLs are more of a “framework” to define business rules; then rules then encode the actual domain logic.
design and implement a business rules language. Then implement it in JS and show me some examples
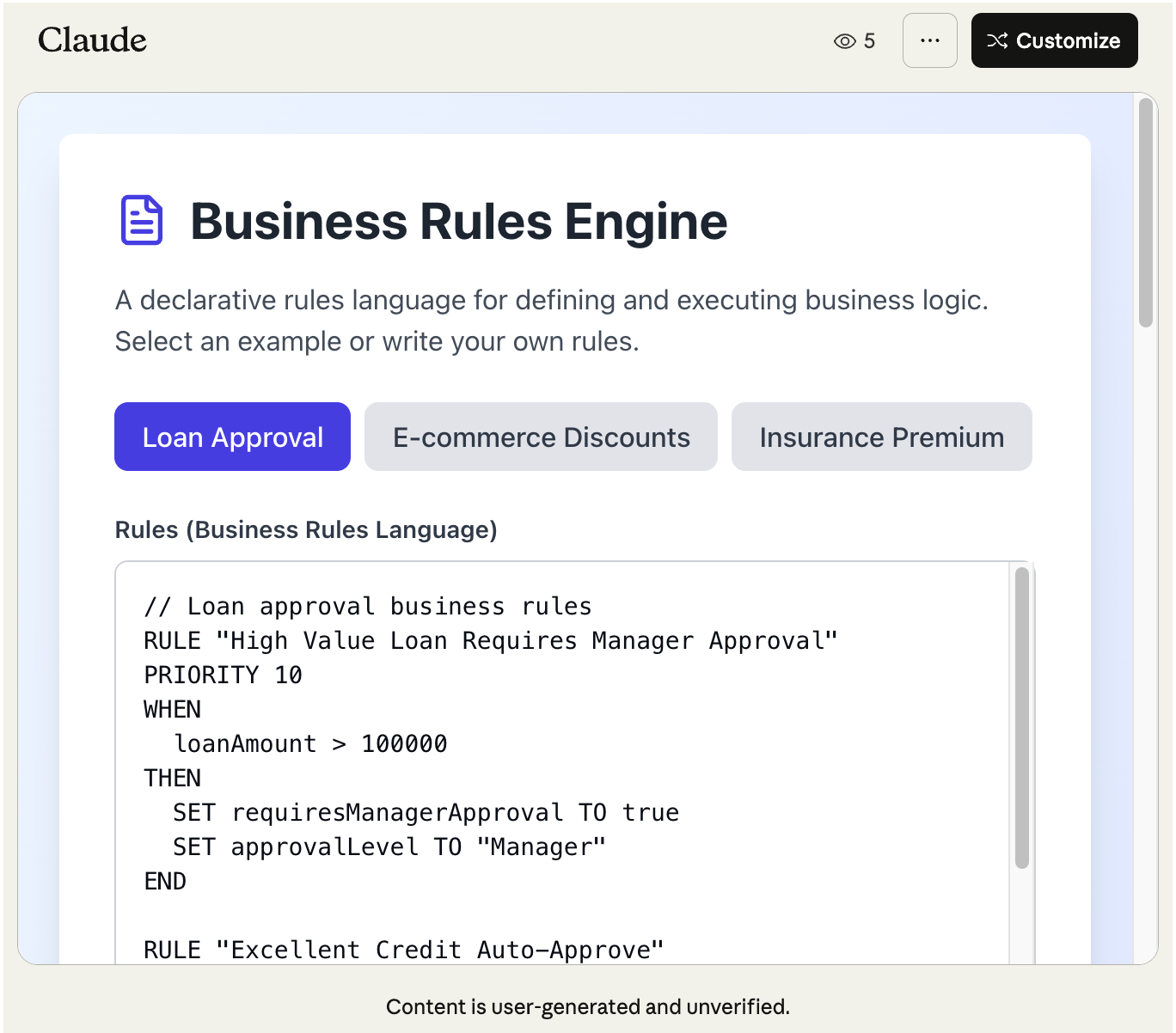
Now, if you ignore that this is clearly reminiscent of Drools to the point of plagiarism, and that the implementation is really poor, you still got a functional PoC, with the added benefit that the LLM is fully aware of the syntax and can assist you in iterating over it.
The goal here isn’t necessarily to implement a language perfectly; instead we can quickly iterate on a prototype, possibly delivering this to end users, while the implementation is improved. After all, this is exactly how the original LOP paper proposed to carry on the work!
What About Maintainance? 🔗
A common critique about the cost of maintaining and working with DSLs is that you now have to maintain not just documentation but also tooling. With the advent of LLMs, these special-purpose, small languages are much more cost-effective.
- docs and examples can be very often generated by the LLM itself.
- if the main interaction pattern is code-gen via an LLM, there is far fewer pressure to implement comprehensive tooling, such as a full IDE integrations, because a coding agent might be happy enough with a CLI tool or an MCP server. Other, simpler things, like syntax coloring, can be generated as well.
Another common critique is about the cost of defining an external DSL as opposed to an internal DSL.
An external DSL is the type of language that we have shown in this blog post, with its own syntax, parser, interpreter/compilation pipeline.
An internal or embedded DSL (also “fluent interface”) is a style of library design where function or method invocations are chained together to form “sentences”. For instance, Martin Fowler’s classic essay mentions JMock:
mock.expects(once()).method(“m”).with( or(stringContains(“hello”), stringContains(“howdy”)) );but I am sure nowadays you’ll have seen plenty of those. The more the syntax of your “host” language is flexible, the more your “internal” DSL will look like its own language. For instance, at some point Scala was notorious for going a bit too wild with operators. The benefit of this style is that you don’t need to define your own parser and tooling. The downside is that the “host” language is not really aware of your “guest” language, so error messages might be more inscrutable.
Depending on how flexible your language is, the boundaries between internal and external DSLs might blur: for instance Racket allows you to define your own syntax in term of the core syntax; in fact Rhombus is a recent addition to the family, with whitespace-delimited, Python-like syntax.
In general, the way you will implement your language is really a detail, at this point. But because of the way LLMs change language economics, I would argue that the cost of defining your own syntax instead of leaning onto the host language’s is now much lower; in fact, I would even dare to say that you might want to prefer flexible syntax, so that you will be able to optimize for token cost.
Conclusions 🔗
Over the years the pendulum has swung back and forth, when it comes to domain-specific languages. In late 2000s and early 2010s there was an explosion of newer programming languages, and there was a lot of excitement around DSLs, including Debasish Ghosh’s classic “DSLs in Action”3.
In recent years, there has been something of a “winter” in DSL design and development due to the high maintenance costs and the tooling expectations from end users. This blog post explored the syntactic dimension of “token-efficiency” in DSL design: I invite you to explore more of this space, including semantics; I, for one, will welcome more crazy DSL implementations!
I hope that with the avalanche of changes AI is bringing to our daily lives, it will also ignite a renewed wave of enthusiasm for language design.
If it won’t, well, I know I’ll find a way.
Yes, I hear you: context windows are getting larger; however, research has shown that performance may suffer at much smaller lengths than the theoretical maximum context size. e.g.:
- Context Is What You Need: The Maximum Effective Context Window for Real World Limits of LLMs (Paulsen, 2025)
- Context Length Alone Hurts LLM Performance Despite Perfect Retrieval (Du et al., 2025)
- LLM Effective Context Limits – Why Does the Effective Context Length of LLMs Fall Short? (October 2024)
Throughout the rest of the post, we used
tiktokenwithcl100k_base, used by GPT-4 and similar to Claude’s (tiktoken.get_encoding("cl100k_base")) ↩︎In fact, Guglielmo Iozzia is currently writing a book about Domain-Specific Small Language Models. ↩︎